目录
模型
在 AI 领域中,模型一词有多种含义,具体取决于上下文:
模型方法/结构(methodology/model architecture):
指的是一种用于解决特定任务的算法结构或网络设计方案,由科研人员提出。例如 BiSeNet、ResNet、Transformer 等。这些是“如何构建模型”的指导思路或框架,本质上是一种方法论,还不能直接使用,需要实现和训练。
训练好的模型文件(trained model):
指开发者使用特定数据和算法,根据上述方法论训练出的具体模型参数文件(如 .pth、.onnx 文件),可以直接用于预测或部署。
模型代码/工程实现:
指根据某种方法论实现的完整训练或推理工程,包括网络结构定义、训练逻辑、数据加载、推理接口等部分,通常以开源项目或仓库形式存在。
📌 示例说明:BiSeNet 是一种模型结构(第 1 种含义),而某 GitHub 仓库提供的代码实现(第 3 种)可以用来训练它,最终得到的 .pth 文件就是一个可用模型(第 2 种)。
算法
模型的核心是算法.
算法贯穿模型整个生命周期:从一个新模型的提出(其实就是新算法的提出或新组合),到模型的工程实现(其实就是算法的实现)。最后生成模型文件(文件内就是编译后的算法代码)。
一个模型可以通过多种算法组合,开发者需要根据需求选择适用的算法来训练模型。
以下是一些常用的算法:
| 功能类别 | 算法作用 | 代表性算法 | 应用场景示例 |
|---|---|---|---|
| 模型训练(优化) | 优化模型参数,使损失函数最小化 | - 梯度下降(Gradient Descent) - Adam(Adaptive Moment Estimation) | 神经网络训练(CNN、RNN、Transformer 等) |
| 损失函数计算 | 衡量模型预测与真实标签之间的差距 | - 均方误差(MSE) - 交叉熵损失(Cross-Entropy) | 回归与分类任务中的模型优化 |
| 特征提取(深度学习特有) | 从原始数据中自动提取高级特征 | - 卷积运算(Convolution) - 循环结构(如 LSTM 单元) | 图像识别、语音识别、文本生成 |
| 激活与非线性变换 | 增加神经网络表达能力,避免线性模型的局限 | - ReLU(Rectified Linear Unit) - Sigmoid / Tanh | 深度学习各类网络结构的隐藏层 |
| 降维与特征选择 | 简化模型、提高效率、减少过拟合 | - 主成分分析(PCA) - L1 正则化(Lasso) | 图像压缩、特征冗余过滤 |
| 分类 | 判断输入属于哪个类别 | - 支持向量机(SVM) - 决策树 | 图像分类、垃圾邮件识别 |
| 回归 | 预测连续值 | - 线性回归 - 随机森林回归 | 房价预测、销量预测 |
| 聚类 | 将数据自动分组 | - K-Means - 层次聚类(Hierarchical Clustering) | 客户分群、图像分割 |
| 降噪与正则化 | 防止模型过拟合,提升泛化能力 | - Dropout - L2 正则化(权重衰减) | 深度神经网络训练 |
| 初始化算法 | 为模型参数设定初始值,便于收敛 | - Xavier 初始化 - He 初始化 | 深度神经网络训练 |
| 模型集成 | 提高模型准确率与鲁棒性 | - 随机森林(Random Forest) - 梯度提升树(GBDT) | Kaggle 冠军常用策略 |
| 搜索与决策优化 | 在复杂环境中做出决策 | - 强化学习(Q-learning) - 蒙特卡洛树搜索(MCTS) | 游戏AI、机器人控制 |
例如:卷积神经网络等神经网络模型 就是使用了多个已知的基础算法组件,形成的一种新的神经网络结构或框架。
人工智能模型分类
比较火热的AI模型根据模型的实际用途可以分为:
- 预测式AI模型
- 代理式AI模型
- 生成式AI模型
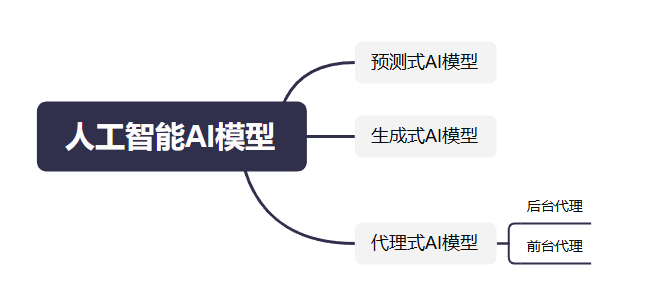
某些模型可能既是代理式,也可能是生成式,例如大语言模型LLM。
根据模型使用的算法不同,可以分为:
- 机器学习模型
- 非机器学习模型
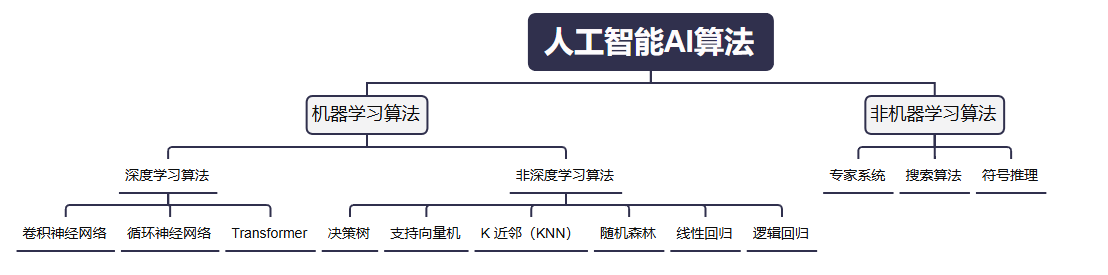
我们关心的主要是:其智能行为是否来源于“从数据中学习”的过程。 如果它是通过算法对大量数据进行训练,并能在新数据上泛化出预测或决策,那它属于机器学习模型。
如果它是通过人手设计规则、流程或逻辑表达,则不属于机器学习模型。
机器学习
机器学习是人工智能的一个子领域,它通过让计算机“学习”大量数据,从而实现自动预测或决策,无需明确编程。
深度学习 vs 非深度学习
机器学习模型还可分为深度学习模型和非深度学习模型,核心区别:模型结构是否是“深层神经网络”。
| 对比维度 | 深度学习(Deep Learning) | 非深度学习(传统机器学习) | 说明 |
|---|---|---|---|
| 是否属于机器学习 | ✅ 是机器学习的子集 | ✅ 是机器学习的子集 | 二者都属于人工智能下的机器学习范畴 |
| 是否需要训练数据 | ✅ 需要大量数据 | ✅ 需要数据(量可小) | 都需要通过数据训练模型 |
| 训练过程 | 使用反向传播、梯度下降等优化算法 | 使用不同算法(如决策树、SVM等)进行训练 | 本质上都包含“训练-测试”流程 |
| 特征工程 | ❌ 通常不需要手工特征工程,能自动学习特征 | ✅ 需要大量人工特征设计与选择 | 深度学习更强在自动提取特征 |
| 模型结构 | 多层神经网络(深层、复杂) | 模型结构较简单(树、线性函数等) | 深度模型可处理更复杂的数据分布 |
| 对数据量的需求 | 很高(大量标注样本) | 相对较低 | 数据越多,深度学习效果越明显 |
| 计算资源需求 | 高(通常需要 GPU/TPU) | 低(普通 CPU 即可) | 影响训练时间和部署成本 |
| 适用数据类型 | 非结构化数据(图像、语音、文本)表现优越 | 结构化数据(表格数据)更合适 | 应用场景不同 |
| 可解释性 | 差(黑箱模型) | 好(可以解释决策路径) | 决策树、线性模型易解释 |
| 常见算法/模型 | CNN, RNN, Transformer, BERT, GPT | 决策树、随机森林、SVM、KNN、朴素贝叶斯、线性回归等 | 深度学习更偏向神经网络体系 |
| 训练时间 | 长 | 短 | 模型复杂度决定训练周期 |
| 部署难度 | 高 | 低 | 深度模型体积大、依赖多 |
| 适合任务示例 | 图像识别、语音识别、自然语言处理、自动驾驶等 | 表格分析、金融风控、医学诊断、用户流失预测等 | 各有擅长领域 |
深度学习模型主要使用卷积神经网络,循环神经网络等算法 非深度学习模型主要使用决策树,支持向量机(SVM),K 近邻(KNN),随机森林,线性回归 / 逻辑回归等算法。
学习方式分类
根据机器学习系统的学习方式,可以将机器学习算法分为:
- 监督式学习算法
- 非监督式学习算法
- 强化学习算法
非监督式学习算法
非监督式学习模型通过获得不含任何正确答案的数据来进行预测。非监督式学习模型的目标是找出数据中具有意义的模式。换句话说,模型没有关于如何对每项数据进行分类的提示,而是必须推断自己的规则。 一种常用的非监督式学习模型采用了一种称为聚类的技术。该模型会查找可划分自然分组的数据点。 **聚类与分类不同,因为类别不是由您定义的。**例如,无监督模型可能会根据温度对天气数据集进行分组,从而揭示定义季节的分片。然后,您可以尝试根据对数据集的理解为这些集群命名。
强化学习算法
强化学习模型根据在环境中执行的操作获得奖励或惩罚,从而进行预测。强化学习系统会生成政策,定义用于获得最多奖励的最佳策略。 强化学习用于训练机器人执行任务(例如在房间内四处走动),以及训练 AlphaGo 等软件程序玩围棋。
监督式学习算法
监督式学习的两种最常见用例是回归和分类。 回归模型可预测数值。例如,用于预测降雨量(以英寸或毫米为单位)的天气模型就是回归模型。 分类模型可预测某个对象属于某个类别的可能性。与输出为数字的回归模型不同,分类模型输出一个值,用于表明某个对象是否属于特定类别。
很多算法都属于监督式学习算法:
- 监督式学习算法:线性回归、逻辑回归、Lasso回归、Ridge回归、线性判别分析、近邻、决策树、感知机、神经网络、支持向量机、AdaBoost、GBDT、XGBoost、LightGBM、CatBoost、随机森林
- 非监督式学习算法:聚类算法
- 强化学习算法
- 生成式AI算法
工程实现名词解释
pytorch
PyTorch 是一个用于构建、训练和部署神经网络模型的工具框架。由fackbook开发
模型训练
一个模型的工程实现,不仅包含论文中提出的核心算法的代码开发,还包括完整的训练与推理流程实现:
数据处理:如自定义数据加载器、图像增强、格式转换等;
训练过程设计:包括损失函数、优化器、学习率调度器、梯度控制、混合精度训练等;
模型评估与验证:如交叉验证、mIoU、F1 分数等指标评估;
推理与部署接口:实现模型导出、部署(如 ONNX、TensorRT)、性能优化等。
因此,模型工程实现不仅是“代码复现”,更是“系统性构建”——确保模型从训练到部署的完整闭环。
以 BiSeNet 为例:论文作者并未提供完整的官方训练代码,很多人会参考社区的复现项目来使用,比如: https://github.com/CoinCheung/BiSeNet 这是一个较为流行的实现版本,支持 BiSeNet 和 BiSeNetV2,并包含完整的训练、验证、推理流程。
CUDA
英伟达显卡主要的功能是并行计算,所以将显卡用来做实时图像渲染(玩游戏),但是基于并行计算可以完成很多其他功能,例如深度学习,图像处理,大数据分析等。因此,英伟达推出CUDA,其是一个并行计算平台和编程模型,它允许开发者使用 C、C++、Fortran 以及 Python(通过库) 等编程语言,直接在 NVIDIA 的 GPU(图形处理器) 上进行通用计算。
使用CUDA训练时,必须选择对应自己显卡CUDA版本的框架,执行 查看版本。
CPU训练 vs GPU训练
CPU的本职工作就是计算,因此可以使用CPU进行计算,但是CPU并行计算能力没有GPU好。所以训练效果上GPU要好于CPU。